Hibernate基础
Hibernate
初识
加载过程
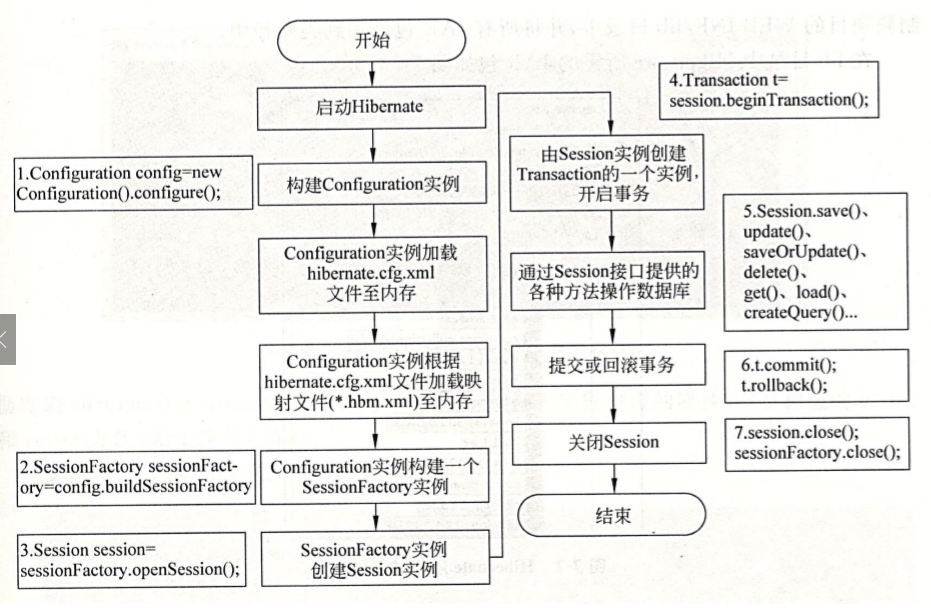
Hibernate全局配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
<hibernate-configuration>
<session-factory>
<!-- 设置数据库驱动 -->
<property name="hibernate.connection.driver_class">com.mysql.jdbc.Driver</property>
<!-- 设置数据库URL -->
<property name="hibernate.connection.url">jdbc:mysql://localhost:3306/hibernate?useUnicode=true&characterEncoding=utf-8</property>
<!-- 数据库用户名 -->
<property name="hibernate.connection.username">root</property>
<!-- 数据库密码 -->
<property name="hibernate.connection.password">369cc</property>
<!-- 指定对应数据库的方言,hibernate为了更好适配各种关系数据库,针对每种数据库都指定了一个方言dialect -->
<property name="hibernate.dialect">org.hibernate.dialect.MySQLDialect</property>
<!--显示sql语句 -->
<property name="hibernate.show_sql">true</property>
<!--格式化sql语句 -->
<property name="format_sql">true</property>
<!--自动生成表 -->
<property name="hibernate.hbm2ddl.auto">update</property>
<!-- 映射文件 -->
<mapping resource="hbm/User.hbm.xml"/>
<mapping resource="hbm/Order1.hbm.xml"/>
<mapping resource="hbm/Customer.hbm.xml"/>
</session-factory>
</hibernate-configuration>Hibernate映射文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
<hibernate-mapping>
<!-- class配置了对象和表的关系 -->
<class name="com.smart.zero.domain.Order1"
table="orders"> <!-- id元素是用来配置主键字段和属性关系的 name:属性名 column:字段名 type:两者者之间转换时使用的类型 -->
<id name="id" type="integer" column="oid">
<generator class="native"/><!-- 用来指明主键生成方式 -->
</id>
<!-- property元素是用来配置普通字段和属性关系的 -->
<property name="address" length="50" type="string" column="address"/>
<property name="price" type="double" column="price"/>
<!-- 配置映射 -->
<!-- <many-to-one>标签 name :关联对象的属性的名称. column :表中的外键名称. class :关联对象类的全路径 -->
<many-to-one name="customer" column="cno" class="com.smart.zero.domain.Customer"/>
</class>
</hibernate-mapping>
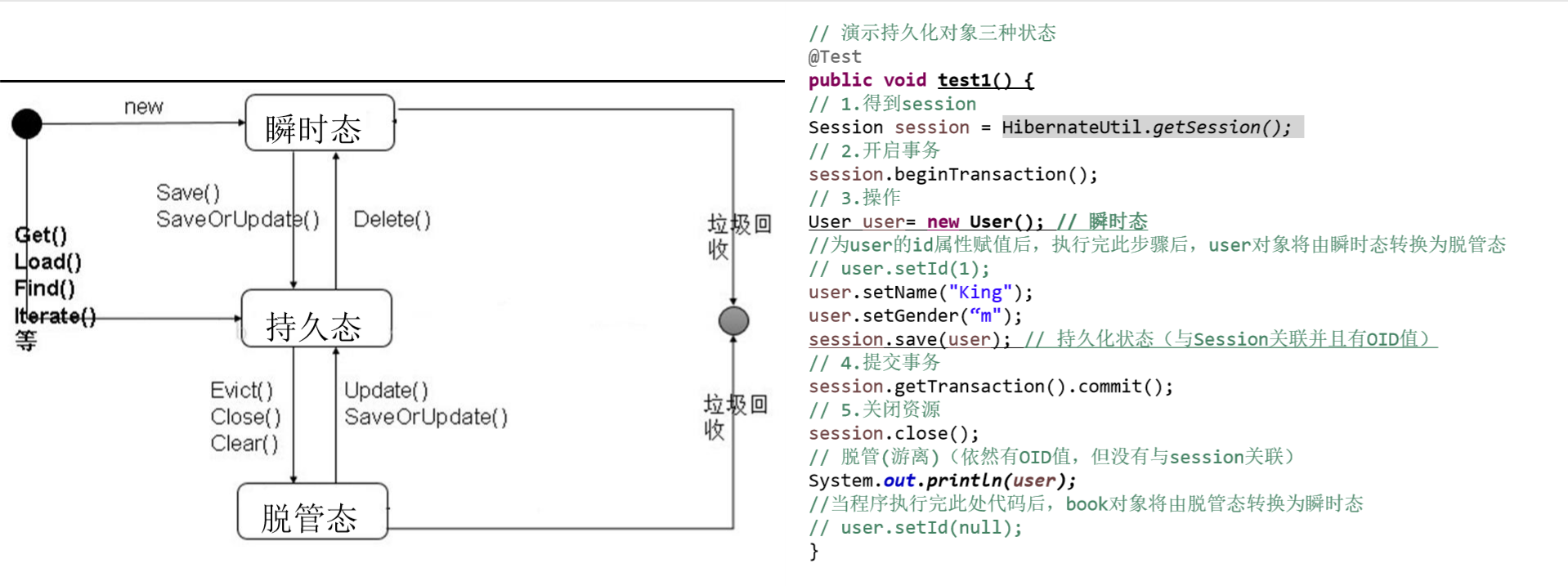
Hibernate持久化对象的三种状态

瞬时态
由java的new命令开辟内存空间的java对象也就是普通的java对象,如果没有变量引用它它将会被JVM收回。临时对象在内存中是孤立存在的,它的意义是携带信息载体,不和数据库中的数据有任何的关联。通过Session的save()方法和saveOrUpdate()方法可以把一个临时对象和数据库相关联,并把临时对象携带的信息通过配置文件所做的映射插入数据库中,这个临时对象就成为持久化对象。
持久态
持久化对象在数据库中有相应的记录,持久化对象可以是刚被保存的,或者刚被加载的,但都是在相关联的session声明周期中保存这个状态。如果是直接数据库查询所返回的数据对象,则这些对象和数据库中的字段相关联,具有相同的id,它们马上变成持久化对象。如果一个临时对象被持久化对象引用,也立马变为持久化对象。
如果使用delete()方法,持久化对象变为临时对象,并且删除数据库中相应的记录,这个对象不再与数据库有任何的联系。
持久化对象总是与Session和Transaction关联在一起,在一个session中,对持久化对象的操作不会立即写到数据库,只有当Transaction(事务)结束时,才真正的对数据库更新,从而完成持久化对象和数据库的同步。在同步之前的持久化对象成为脏对象。
当一个session()执行close()、clear()、或evict()之后,持久化对象就变为离线对象,这时对象的id虽然拥有数据库的识别值,但已经不在Hibernate持久层的管理下,他和临时对象基本上一样的,只不过比临时对象多了数据库标识id。没有任何变量引用时,jvm将其回收。
游离态
Session关闭之后,与此Session关联的持久化对象就变成为脱管对象,可以继续对这个对象进行修改,如果脱管对象被重新关联到某个新的Session上,会在此转成持久对象。
脱管对象虽然拥有用户的标识id,所以通过update()、saveOrUpdate()等方法,再次与持久层关联。
下面我们就通过使用hibernate,实现对数据库的增删改查来体现三种状态之间的转换过程。
- 状态转换
一级缓存
缓存
缓存介于应用程序和永久性数据存储源之间,其作用是降低应用程序直接读写永久性数据存储源的概率,从而提高应用程序的运行性能,缓存的物理介质通常是内存;
一级缓存
hibernate的缓存分为一级和二级缓存,两者都位于持久化层,存储的都是数据库数据的备份,其中一级缓存为hibernate的内置缓存,不能卸载
hibernate的一级缓存就是指session缓存,session缓存是一块存储空间用来存放相互管理的Java对象,在使用hibernate查询对象的时候,首先会使用对象属性的oid值在session缓存中查找,如果找到了就会直接从session中提取,不会再查询数据库如果没有找到匹配的,则回去数据库查询,并且把找到的数据存入session缓存中。一级缓存就是为了减少对熟虑库的访问次数。
在Session 接口的实现中包含一系列的Java集合,这些Java集合构成了Sesion 缓存。只要Session实例没有结束生命周期,存放在它缓存中的对象也不会结束生命周期。固一级缓存也被称为是Session基本的缓存。
- Hibernate的一级缓存有如下特点:
- 当应用程序调用Session接口的save()、update()、 saveOrUpdate 时,如果Session缓存中没有相应的对象,Hibernate就会自动的把从数据库中查询到的相应对象信息加入到一级缓存中去。
- 当调用Session接目的load()、get()方法, 以及Query接口的list()、iterator()方法时,会判断缓存中是否存在该对象,有则返回,不会查询数据库,如果缓存中没有要查询对象,再去数据库中查询对应对象,并添加到一级缓存中。
- 如果调用了session的close()方法,则缓存会被清空
- Hibernate的一级缓存有如下特点:
快照
Hibemate向一级缓存放入数据时,同时复制一份数据放入到Hibernate快照中,当使用commit()方法提交事务时,同时会清理Session的一级缓存, 这时会使用oid判断一级缓存中的对象和快照中的对象是否一致,如果两个对象中的属性发生变化,则执行update语句,将缓存的内容同步到数据库,并更新快照:如果一致,则不执行update语句。
- Hibermate快照的作用就是确保一级缓存中的数据和数据库中的数据一致
- 快照的根本作用是保证数据一致性,保证数据一致的另一种做法是,commit之前把堆内存中的数据直接与数据库中的对应记录进行对比,显而易见这样的效率是灰常低下的,而采用快照技术,因为快照是一定和数据库中记录一致的,快照也在堆内存中,所以速度不是一般的快。(如果没有变化的话,堆内存的数据于同在堆内存的快照比较的速度肯定要比堆内存的数据于数据库)
常见操作
clear():清除session中的缓存数据(不管缓存与数据库的同步)。flush():将session的缓存中的数据与数据库同步。执行完session.flush()时,并不意味着数据就肯定持久化到数据库中的,因为事务控制着数据库,如果事务提交失败了,缓存中的数据还是照样会被回滚的。
refresh():reflush操作会使数据库记录与session缓存记录保持一致,也就是是说会强制向数据库发送一条select语句。
hibernate控制反转
-
何为控制反转, 比如 Poeple(人) 和 Address(地址) :一个人可以拥有多个地址,那么在配置的时候 在Poeple.hbm,xml 中 设置 one-To-Many (先不考虑Address配置文件) 那么Ok 当我们向People对象 添加 新的地址时 调用代码
1
2
3
4
5
6
7
8
9People p = new People(“王三”);
Address address = new Address("公司地址");
p.getAddress().add(address) ;
save(p);
save(address);当我们查看 控制台输出的语句会发现 有两个insert 语句 和一个 update 语句 显然这是非常消耗性能的 ,正确的应该是 只有两个 insert
现在我们分析下 hibernate 的操作 先保存了People 之后 保存了 Address 最后又修改了 Address 的 关联的peopleId 外键属性 这是由于Address 的外键值是由Poeple来控制的
现在我们在People 的 配置文件中 加上 inverse=”true” 在执行上诉步骤 会发现 只有两条Insert 语句
查询
导航对象图检索
- 根据已加载的对象导航到其他对象。利用类与类之间的关系来检索对象。
1
2
3Order order=(Order)session.get(Order.class);
Customer customer=order.get(Customer);
- 根据已加载的对象导航到其他对象。利用类与类之间的关系来检索对象。
投影查询
- 查询对象部分属性
1
2
3String HQL="select u.name,u.password from User as u"//此时必须要select
Query query=session.createQuery(HQL);
List<Object[]> list=query.list()//注意list存放的是Object数组
- 查询对象部分属性
动态实例查询
- 在投影查询时,返回的查询对象是一个对象数组,操作起来并不是很方便。所以将投影查询的返回结果重新组成一个实体的实例,这就是动态实例化查询。
1
2
3
4
5
6
7
8
9
10
11Strng HQL="selct new User(u.name,u.password) from User as u";
Query query=session.createQuery(HQL);
List<User> list=query.list();
//必须要有相应的构造方法
public User(String name,String password){
super();
this.name=name;
this.password=password;
}
- 在投影查询时,返回的查询对象是一个对象数组,操作起来并不是很方便。所以将投影查询的返回结果重新组成一个实体的实例,这就是动态实例化查询。
条件查询
- 使用
where,like等- 按参数位置查询
- 使用
?来定义参数的位置,然后利用Query对象的Setter方法为其赋值,类似于JDBC的PrepareStatement对象的参数绑定方法。1
2
3
4
5
6
7
8
9
10
11
12
13String HQL="from User where name=? and id=?";
Query query=session.createQuery(HQL);
query.setString(0,"JONE");
query.setInteger(1,3);
User user=(User)query.uniqueResult();
////
String HQL="form Uesr where name like ?";
Query query=session.createQuery(HQL);
query.setString(0,"%o%")//模糊查询
List<User> list=query.list();
- 使用
- 按参数名称查询
- 在HQL中自定义
1
2
3
4
5String HQL="form Uesr where name=:name and id=:id";
Query query=session.createQuery(HQL);
query.setParameter("name","Kity")
query.setParameter("id","5")
List<User> list=query.list();
- 在HQL中自定义
- 按参数位置查询
- 使用
分页查询
setFirstResult(int firstResult);设定查询位置setMaxResult(int maxReslut);设定插叙数目1
2
3
4
5String HQL="form Uesr";
Query query=session.createQuery(HQL);
query.setFirstResult(2);//从第3条数据开始查询
query.setMaxResult(3);//查询3条记录
List<User> list=query.list();
报表查询
1
2
3
4
5
6
7
8
9
10String HQL="select u.gender,count(u) form Uesr as u group by u.gender";
Query query=session.createQuery(HQL);
List<User> list=query.list();
Iterator iter=list.iterator();
while(iter.hasNext()){
Object[] objct=(Object[])iter.next();
Sy
}QBC查询
组合查询
- 通过Restrictions工具类的相应方法
方法 说明 1 1
1
2
3
4
5
6
7
8
9Criteria criteria=session.createCriteria(User.class);
criteria.add(Restrictions.and(Restrictions.eq("")))
////
Criteria criteria=session.createCriteria(User.class);
Criterion criterion=Restrictions.or(Restrictions.eq("id",1),Restrictions.eq("name","Kitty"));- 通过Restrictions工具类的相应方法
分页查询
setFirstResult(int firstResult);setMaxResult(int maxReslut);
1
2
3Criteria criteria=
criteria.setFirstResult(2);
criteria.setMaxResult(3);
Spring
基础知识
以IOC(Inverse Of Control 控制反转) 和 AOP(Aspect Oriented Programming 面向切面) 为内核
三层
- 表示层(web)
- 业务逻辑(service)
- 持久层(dao)
优点
- 简化开发
- 方便测试
- 松耦合
- AOP编程的支持(权限拦截,任务监控)
- 方便集成各种优秀框架
- 降低JavaEE API的使用难度
Spring的体系结构
Core Container(核心容器)
- Beans 提供了BeanFactory
- Core
- Context 建立在core和Beans模块基础之上
- Expression Language 运行时查询和操作对象
Data Access/Integration(数据访问/集成)
- JDBC
- ORM
- OXM
- JMS:Java消息
- Transaction
Web模块
- web 提供基本的Web开发集成特性
- Servlet
- Struts
- Portlet
其他模块
- AOP
- Aspects
- Instrumentation
- Test 指出Spring组件,使用JUnit或者TestNG进行测试
Spring的IOC容器
- Spring容器会负责程序之间的关系,而不是有程序代码直接控制,这样控制权由应用代码转移到外部容器,控制权发生了反转,这就是Spring的IOC(控制反转)思想
- BeanFactory
- ApplicatonContext
- Spring容器会负责程序之间的关系,而不是有程序代码直接控制,这样控制权由应用代码转移到外部容器,控制权发生了反转,这就是Spring的IOC(控制反转)思想
RESTful风格
发布时间: 2020-04-22 1:40:10
更新时间: 2022-04-21 16:34:30
本文链接: https://wyatt.ink/posts/Code/30225.html
版权声明: 本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!